대망의 마지막 챕터다.
우리는 늘 흐르는 시간 속에 살고 있다.
그것을 다룬 것 시계열 데이터다.
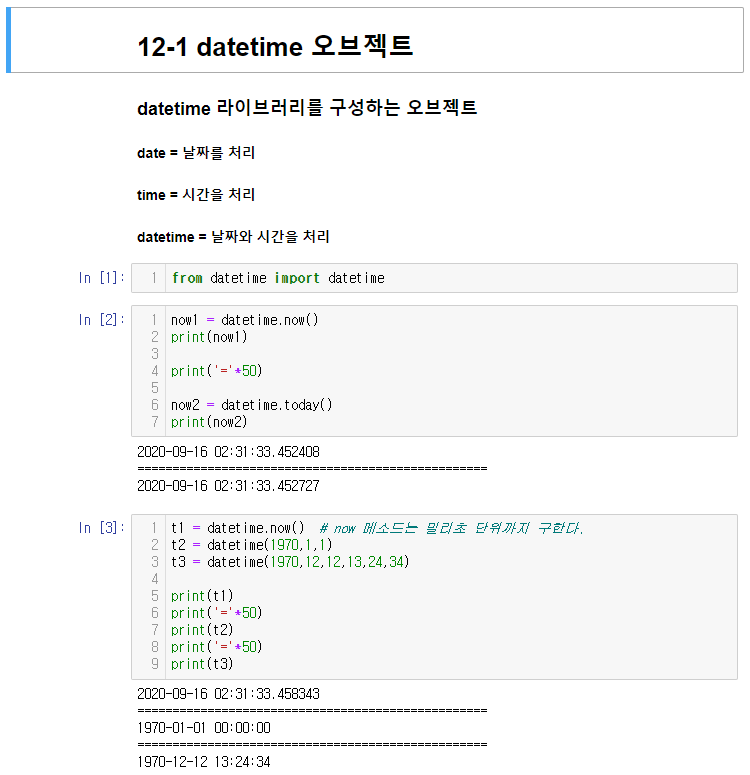
datetime은 기본적으로 날짜와 시간을 처리하기 위한 것이다.
now 메소드는 밀리초단위까지 현재 시간을 구한다.

당연히 시간을 계산하기 위해 사용하며 이로 변환하기 위해서는
to_datetime 메소드를 사용하면 된다.

데이터 프레임 정보를 살펴보면 Date가 object 타입으로 들어가 있다.

date_dt라는 것을 새로 만들고 Date를 타입 변경하여 내용을 채운다.

시간 형식 지정자들을 이용해 입력하면 원하는 포맷으로 출력이 가능하다.

다양한 시간 형식 지정자와 그 결과다.
필요한 부분은 꼭 메모해서 이용하도록 하자.

시계열 데이터 구분해서 추출하는 파트다.
strftime 메소드와 시간 형식 지정자를 이용해서 잘라낸다.

datetime 오브젝트로 변환하려는 열을 지정해서 불러오는 것이 더 편리하다.
아니면 필요한 부분만 발췌하여 변환도 가능하다.
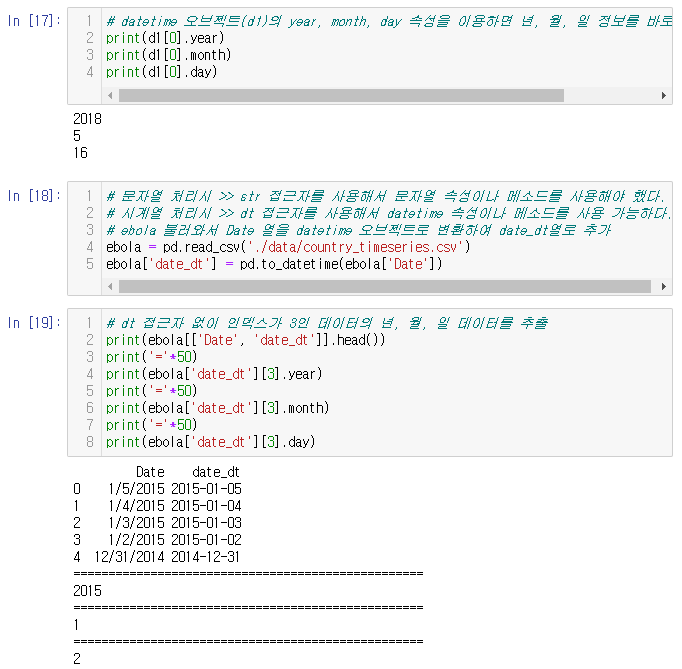
연월일도 따로 출력 가능하다.
문자열과 시계열 처리 시 str과 dt 접근자를 이용해서 사용 가능
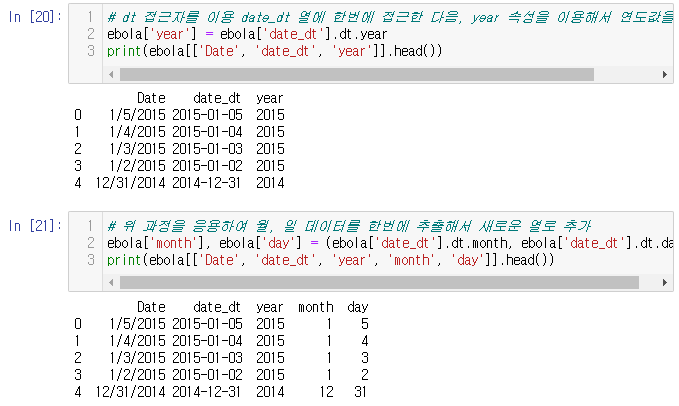
위 과정을 응용해 연월일 데이터를 추출해 새로운 컬럼으로 추가한다.

18부터 21까지 추가된 내용을 확인하면,
date_dt는 datetime64 타입이고,
year, month, day는 int64 타입이다.

각 사례별로 시계열 데이터 계산하는 예시다.
시간 역순으로 정렬되어 있기 때문에 거꾸로 조회한다.
min값을 조회해서 최초 발병일을 찾을 수 있다.
진행 정도를 파악하기 위해선 각 Date에서 최초 발병일을 빼면 된다.

다음은 파산한 은행 수를 구하는 것이다.

위의 데이터 프레임에 담는 방식과는 차이점이 datetime으로 파싱 하는 것이다.

각 연도별로 사이즈를 탐색하면 파산한 은행의 개수를 파악할 수 있다.

그룹화하여 연도별, 분기별로 재 출력한다.

보다시피 너무 길어 한눈에 파악하기 힘드므로 시각화 기능을 이용한다.

다음은 테슬라 주식 데이터를 통해 시간 내용을 계산한다.

Date 컬럼을 datetime으로 파싱 한다.
다음 dt 접근자를 이용해서 2010년 6월 데이터만 불린 추출 한다.

datetime을 데이터 프레임의 인덱스로 설정하면 원하는 시간대의 데이터를 바로 확인할 수 있다.

앞서 작성한 은행 데이터처럼 최초 지정일과 확인하려는 날짜의 차이를 ref_date로 새로 지정한다.
슬라이싱을 통해 최초 5일 간만 수집된 데이터를 출력한다.

4 days는 없기 때문에 출력되지 않았다.
다음으로는 누락 값이 들어가는 시계열 데이터이다.

반드시 Date 컬럼을 인덱스로 지정하고 범위는 위에서 지정한 만큼 이용

시간 범위를 인덱스로 지정하면 우리가 흔히 아는 시계열 데이터로 이용이 가능하며,
freq 매개변수 값을 지정하면 원하는 만큼 간격을 조절하여 이용할 수 있다.

위 매개변수 값을 이용해 원하는 시계열 데이터로 구성해 이용 가능하다.

B라는 매개변수 값을 이용해 평일 데이터만 이용하고, 각 나라별 에볼라 확산속도를 시각화했다.
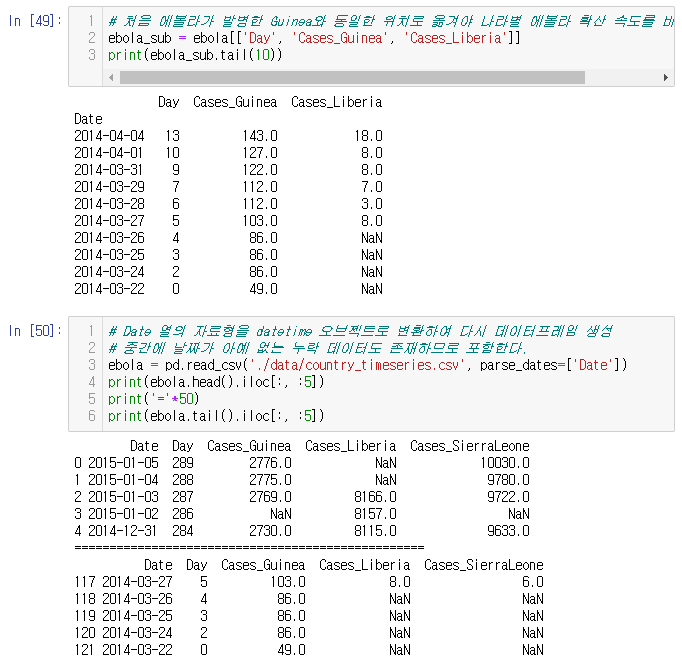
각 나라별 시작일이 다르기 때문에 최초 발병국이 있는 Guinea와 같은 위치로 옮겨야 비교 가능하다.
새로 데이터 프레임을 만들고 중간에 날짜가 없는 데이터도 존재하므로 모두 포함해서 만든다.

날짜 인덱스를 최소와 최대로 지정하여 누락된 부분도 채운다.
시간 순서와 반대로 생성되어 있기 때문에 reversed 메소드를 통해 역순으로 정렬한다.
그리고 새로 인덱스로 지정한다.

last_valid_index는 가장 오래된 데이터를 불러오고
first_valid_index는 가장 최근 데이터를 불러온다.

같은 선상에서 비교해야 하기 때문에 가장 처음 발병한 날로부터 각 나라별 발병일만큼 옮겨주면 된다.

딕셔너리에 시간 형태를 맞춘 데이터가 저장되어있다.

인덱스를 Day로 지정하여 시각화에 필요 없는 Date와 Day열을 삭제하면 그래프용으로 손질이 됐다.

예시로는 이렇게 나와있으나 실상 별로 예쁘지 않아서 맘에 들진 않는다.
이상으로 시계열 데이터까지 도서 전체 1회독을 마친다.
이미지로 많이 붙여 넣은 이유는 이 코드를 복사해서 활용한다는 취지보다는
스터디용으로 결괏값을 참고하면 좋겠다는 생각이 먼저였고,
막 스터디를 시작한 사람들이 공부할 때마저 복붙을 한다면 언제 직접 쳐볼까라는 생각이 들었다.
이번만큼이라도 시간이 들더라도 직접 타이핑해보고 왜 그렇게 되는지 이해를 해보도록 하자.
'공부 > 판다스' 카테고리의 다른 글
| Do it! 데이터 분석을 위한 판다스 입문 - 11 그룹 연산 (0) | 2021.12.17 |
|---|---|
| Do it! 데이터 분석을 위한 판다스 입문 - 10 apply 메소드 활용 (0) | 2021.12.17 |
| Do it! 데이터 분석을 위한 판다스 입문 - 09 문자열 처리하기 (0) | 2021.12.17 |
| Do it! 데이터 분석을 위한 판다스 입문 - 08 판다스 자료형 (0) | 2021.12.16 |
| Do it! 데이터 분석을 위한 판다스 입문 - 07 깔끔한 데이터 (0) | 2021.12.16 |