Do it! 데이터 분석을 위한 판다스 입문 - 07 깔끔한 데이터
깔끔한 데이터
일하다 보면 정말 늘 마주치고 싶은 데이터다.
이번에는 pew 데이터로 스터디를 시작한다.

이번 스터디에서는 '깔끔한 데이터'가 메인이기 때문에 첫 스터디 내용이 행과 열을 위주로 나온다.

id_vars는 열 지정을 해놓고 그 외에 것을 variable로 묶어서 정리한다.

마지막 pew_long으로 종교 기준으로 수입을 묶고,
그것의 전체 개수를 헤아리는 것으로 마무리했다.
그다음으로는 빌보드 차트를 예시로 만든 데이터다.

이 부분에서 중요한 포인트는 Date와 Day를 고정하고,
나머지 행 부분을 피벗 하고 split 메소드를 이용하여 분리한 것이다.

get 메소드를 사용하여 인덱스 내에 데이터를 한 번에 추출한다.
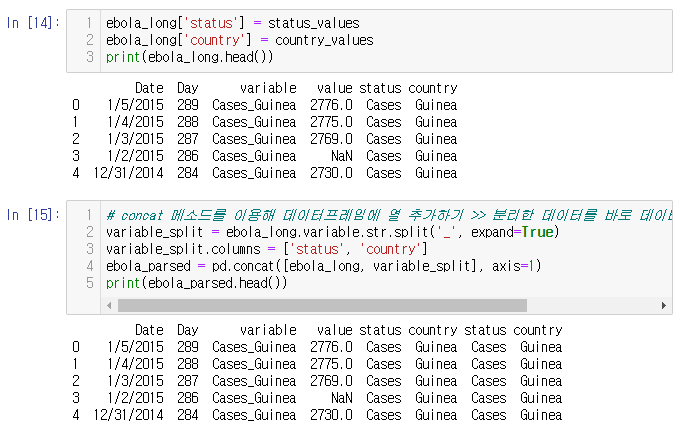
데이터를 쪼개서 필요한 부분을 새 컬럼으로 만들어 다시 합치는 일련의 과정이다.
이 부분은 실제 업무를 하다 보면 많이 쓰일텐데, 필요시 참고하면 좋을 듯하다.

앞서 공부한 내용의 반복이다.

주석으로 예쁘게 정리되어있으니 참고하자.

중복 데이터를 처리하는 방법에 대해 스터디한다.

노래 정보를 주간 순위와 합쳤다. 우리가 흔히 아는 주간 차트의 예시다.

복잡해 보이지만 간단하게 날짜별 데이터가 저장된다는 의미이다.
우리는 glob 라이브러리에 유의하면 될 것 같다.

데이터의 양이 기존에 스터디하던 것보다 월등하게 많다.
이 정도 되면 이제 엑셀에서 작업하기가 힘들다.
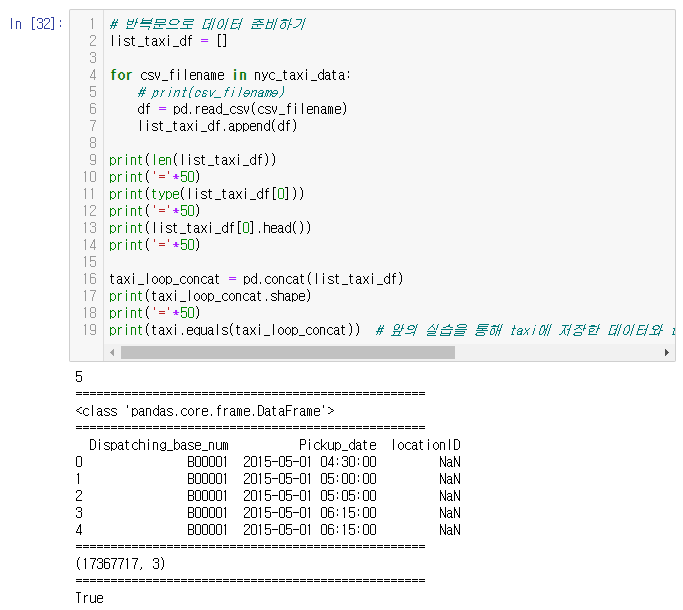
이렇게 많고 반복적인 작업에는 반복문이 딱이다.
각각의 파일을 불러와서 데이터프레임 하나로 추가한다.
해당 구문은 현업에서 정말 많이 쓰일 것 같으니 참고하자!